
This is an informal blog post about the stability of language model features, using mechanistic interpretability to trace the lineage of language model features through fine-tuning, and weight interpolation.
Merging refers to a family of techniques to combine multiple pre-trained models, with different learnt attributes, into a combined model which inherits a meaningful mix of these attributes. In short, by using merging, you should be able to train or fine-tune your way to multiple distinct specialised models, then simply merge them into one avatar model that masters all of the specialised tasks. It is a popular and experimental method to improve model performance without worrying about compute.
Inspired by the emerging field mechanistic interpretability, and Anthropic's work on decomposing language models with dictionary learning1, I want to explore the feature dynamics of model of model interpolation. Specifically, I want to show how to use sparse autoencoders to trace the lineage of features from a base model, through two separate fine-tunes, and finally into a model merged from these two fine-tunes.
In this blog-post, I will be focusing on merging done using spherical linear interpolation (slerp). Model interpolation like this depends on some degree of linear mode connectivity2, requiring the models involved to share base parameters. I will be training one-layer Mistral-like transformer models, with an intermediate multi-layer perceptron (MLP) dimensionality of 1024, all trained with a simple next-token prediction objective on distinct non-overlapping datasets.
I train a base-model on a combination of the BabyLM 100M dataset3 and 10% of the Python subset of The Stack4, then fine-tune two variants on 10% of the Lua subset of The Stack, and all of TinyStories, respectively. The two fine-tuned models are merged, and we end up with the LuaStories model. The resulting family tree of models is shown below in Figure 1.

Model family
All models in the final nuclear model family can be found on HuggingFace:
- BabyLM + Python base model: baby-python-mistral-1L-tiny-base
- Lua fine-tune: baby-python-mistral-1L-tiny-lua-ft
- TinyStories fine-tune: baby-python-mistral-1L-tiny-TinyStories-ft
- LuaStories (Lua + TinyStories) merge: lua-stories-slerp-mistral-1L-tiny
These models all have 37.5M parameters, and in the world of efficient inference of billion parameter models, I can't immediately think of a real-world application for any of them. However, despite their size, these models all produce varying degrees of coherent sequences within their respective domains. This is aligned with the findings of the original TinyStories paper5.
Let me show you.
BabyLM + Python base-model
This model is trained (see hyper-parameters configuration) on simple English (curated child-directed speech, TED talks, subtitles, children's books, British National Corpus), and blocks of Python code chunked with no regard for preservation of semantic structures. Here is a nicely cherry-picked example of a completion of this sentence:
... The sentence is a sentence of the sentence.def fibonacci(self, i):\n return self.get_value(i)Lua fine-tune
This model is fine-tuned (see hyper-parameter configuration) on the entire Lua subset of The Stack.
for a, b in pairs(a) do\n a[a] = a+1\n endTinyStories fine-tune
This model is fine-tuned (see hyper-parameters configuration) on the famous TinyStories dataset. This model is undertrained, compared to the similar single-layer model of the original TinyStories family, with training stopped (prior to convergience) with 0.4 higher cross-entropy validation loss compared to their hi768_nl1 model5 on the same distribution.
Once upon a time, there was a little girl named Lily. She loved to play with her toys and her favorite toy. One day, Lily's mommy asked her to clean up her toys.Merging with slerp
This section is about spherical linear interpolation. Above, I showcase some proof-of-concepts samples from the conventionally tuned models. These will be the effective ancestors our protagonist: the merged Lua + TinyStories model. Spherical linear interpolation (slerp) is a way to interpolate between two points, and is the technique used to merge the Lua and TinyStories fine-tune.
Merging using slerp works by interpolating the weights of two models on a unit sphere. For two paramater sets and , we consider the model parameters as points on a high-dimensional sphere, in our case a 1000+ dimensional one. We then move from our origin model's parameter set to the target model, along the arc connecting the two. To do this, we must first normalise and to make sure that these do definitely lie on the unit sphere.
Once normalised, we can define the merged model weights at fraction along the arc between and on the unit sphere, as given by:
where
for . As we're interpolating from to , corresponds to , and corresponds to .
Example of slerp in 3D
It is not easy to think about circle arcs in high dimensional space, so let me show it in three dimensions. In Figure 2 below, the green point is being slerped between six points.
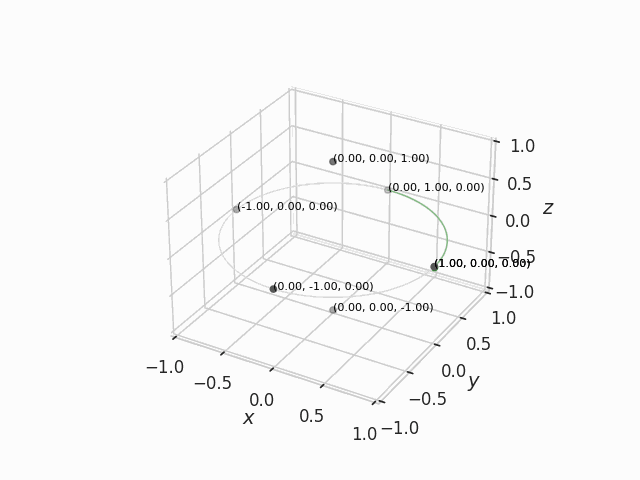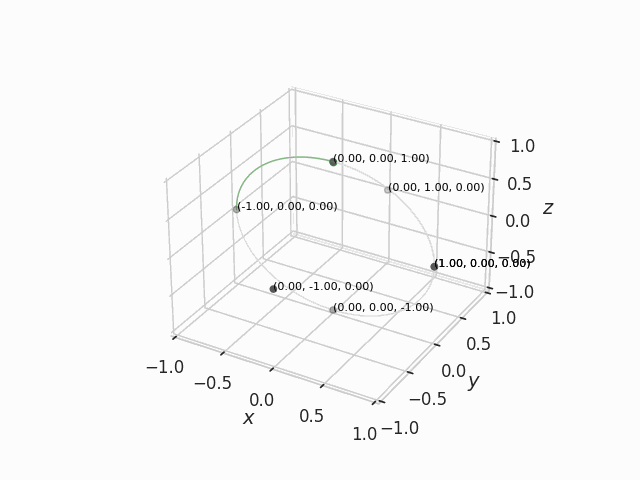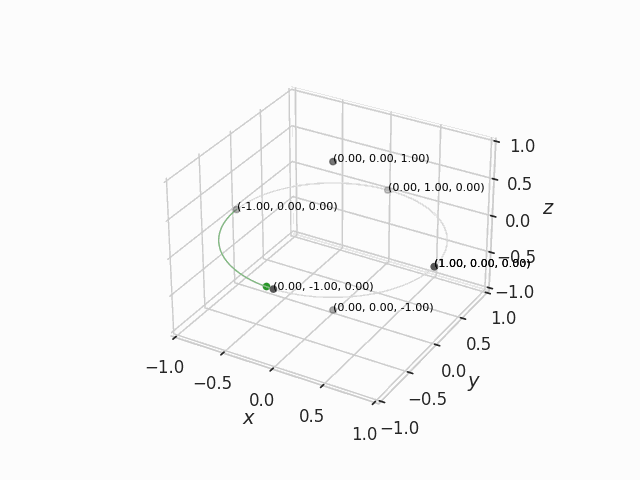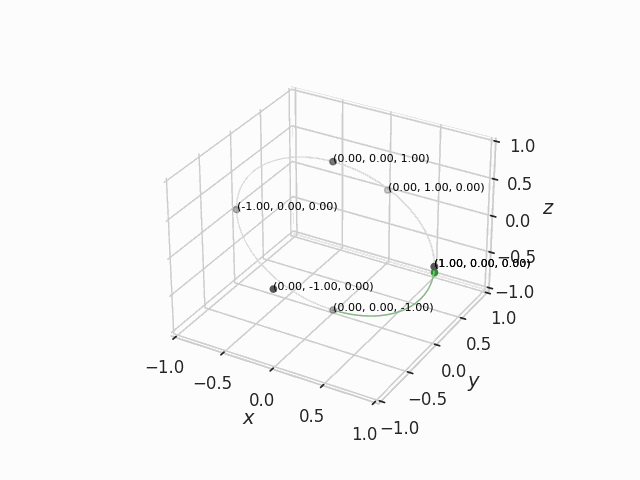
We could think of these points as the weights of a very simple neural network with three input channels and single hidden neuron, defined by the weights connecting the input layer to the neuron where . Our green point is then the slerp merge between the points in the ends of each green arc. Somewhere along the middle of these arcs, the merge model might exhibit a mix of the qualities of the two merged simple neural networks.
Lua + TinyStories = LuaStories
We could choose any along the arc and use it as our merged model. However, in order to get the most interesting merge to study, and to better understand weight interpolation, I evaluate the model with weights for every interpolation step of 5% on both Lua and TinyStories data. This way, we can track how well the model keeps up with the origin model, as it gradually becomes better at performing like the target model. On Figure 3 below, the accuracy of the merged model on the Lua data at each is shown with green lines ( ), and the accuracy of the merged model on TinyStories data at each is shown with gray crossed lines (
), and the accuracy of the merged model on TinyStories data at each is shown with gray crossed lines ( ).
).

Around , we have a model that is equally accurate in predicting Lua and TinyStories data. This is amazing. But not so fast. Remember that our Lua and TinyStories models share the same base model, which one might suspect would perform more or less equally well on Lua and TinyStories data. Therefore the base model's accuracy on both Lua ( ) and TinyStories (
) and TinyStories ( ) have been included as well. We thus verify that in the span our slerps perform better than the base model in both domains.
) have been included as well. We thus verify that in the span our slerps perform better than the base model in both domains.
The LuaStories model at is therefore interesting because it contains significant learnings from both the origin Lua model and target TinyStories model, and we got it by simply interpolating weights. No GPU was harmed in the process.
LuaStories slerp merge
This model is a merge of the Lua and TinyStories models, defined by the weights around half-way along the arc of the hypersphere between the Lua and TinyStories parameter sets, computed using simple spherical linear interpolation. This model quantitatively is within ~20% accuracy of the merged models, and ~20% better than the base model. As seen in below samples, this model qualitatively exhibits both Lua and TinyStories abilities.
Once, there was a big, big tree was a big tree. The tree was a big tree, and a tree. The tree was a tree, and the tree was a tree.while counter do\n for k, v in pairs(v) do\n if k == k and k == kTransformer language model features
Autoregressive transformer language models are tasked to predict the next token (piece of text) in a sequence, given the previous tokens in the sequence. They consist of multiple components, most notably of residual blocks (/ transformer blocks). These residual blocks has an attention mechanism, potentially with multiple attention heads, which analyses the residual stream input of the block, to then write its notes back to the stream. Following the attention mechanism, a residual block contains a feed-forward neural network which, similar to the attention mechanism, processes incoming information and spits new information back to the residual stream. It is within these residual blocks we find the language understanding.
These blocks are stacked in sequence, such that input flows through them, with each block continuing processing of the output of the previous block. At the end of this sequence, the residual stream is converted into a probability distribution over all possible next tokens. Using a lot of data to optimise this probability distribution to consistently predict the correct next token in a sequence, by tweaking the processing circuits of the residual blocks, forces these circuits to compress information/knowledge/intuition embedded in this data.
In short; during training the model learns to read and understand text via abstract processing circuits in the residual blocks.
Features are recipe components
When we merge the Lua and TinyStories models, and the get a model that is a meaningful combination of the two, it is because their merged residual blocks are able to keep processing information more or less like they did before even though their processing circuits are now diluted with those of another model's residual blocks. Each model in our family tree contains its own block with a recipe for how to understand previous tokens in order to predict the next token.
This is one way to think about what is learnt. Recipes of abstract components defining some trait of residual blocks' processing, which together define the model's understanding of language (and beyond).
An example of such a recipe component is this feature in the BabyLM + Python base-model, which looks at previous tokens in the sequence and tracks quotation marks, opening quotation marks following a comma in particular.
Tokens tracked by the feature are highlighted according to how much the feature likes to track them."No," said John, "In reality, that's not how this feature works."
But he was wrong, "Look at this," said Ingrid.
"This feature activates on opening quotes," she continued.
"Okay," he responded, "Especially after a comma like this."
These recipes are stored in the weights of the models' attention mechanism, and in the feed-forward neural network, hidden as individual worker ants in an anthill of neurons that react to seemingly random patterns in the input. It is impossible hard to extract our recipe components (features from hereon) from these neurons, because they are polysemantic and so neuron activations usually don't follow interpretable patterns. One likely reason for this is superposition6, where a neural network learns to represent more independent features of the data than it has neurons, by using a linear combination of multiple neurons to assign features to a direction between neurons - rather using a whole neuron for each feature, it can compress features across many neurons. See Elhage, et al. "Toy Models of Superposition" for more.
Feature genealogy
Sparse autoencoders
In order to find features hiding in superposition, I use sparse autoencoders to learn features from each of the models in the family tree.
Automated interpretability
Conclusion
Appendix
- Bricken, et al., "Towards Monosemanticity: Decomposing Language Models With Dictionary Learning", Transformer Circuits Thread, 2023.↩
- Linear Mode Connectivity and the Lottery Ticket Hypothesis↩
- BabyLM Challenge↩
- HuggingFace: Dataset Card for The Stack↩
- TinyStories: How Small Can Language Models Be and Still Speak Coherent English?↩
- Elhage, et al., "Toy Models of Superposition", Transformer Circuits Thread, 2022.↩